Hashing Table and Binary Tree
A. Hashing Table :
- Circular Single Linked List, Doubly Linked List, & Circular Doubly Linked List
- Stack & Queue
- Hashing Table & Binary Tree
- Binary Search Tree
Circular Single Linked List
• In circular, last node contains a pointer to the first node
• We can have a circular singly linked list as well as a circular doubly linked list.
• There is no storing of NULL values in the list
Advantages of Circular Linked Lists:
1) Any node can be a starting point.
2) Useful for implementation of queue.
3) Circular lists are useful in applications to repeatedly go around the list.
4) Circular Doubly Linked Lists are used for implementation of advanced data structures like Fibonacci Heap.
Doubly Linked List
Double/Doubly linked list (DLL) or two-way linked list is a linked list data structure with
two link, one that contain reference to the next data and one that contain reference to the
previous data.
Advantages over singly linked list:
1) A DLL can be traversed in both forward and backward direction.
2) The delete operation in DLL is more efficient if pointer to the node to be deleted is given.
3) We can quickly insert a new node before a given node.
Disadvantages over singly linked list:
1) Every node of DLL Require extra space for an previous pointer.
2) All operations require an extra pointer previous to be maintained.
Doubly Linked List: Insertion
A node can be added in four ways:
1) At the front of the DLL.
2) After a given node.
3) At the end of the DLL.
4) Before a given node.
Doubly Linked List: Deletion
There are 4 conditions we should pay attention when deleting:
1) The node to be deleted is the only node in linked list.
2) The node to be deleted is head.
3) The node to be deleted is tail.
4) The node to be deleted is not head or tail.
Circular Doubly Linked List
Circular Doubly Linked List has properties of both doubly linked list and circular linked list in
which two consecutive elements are linked or connected by previous and next pointer and
the last node points to first node by next pointer and also the first node points to last node
by previous pointer.
Stacks Concept
A stack is a container of objects that are inserted and removed
according to the last-in first-out (LIFO) principle. In the pushdown
stacks only two operations are allowed: push the item into the stack, and pop the
item out of the stack. A stack is a limited access data structure -
elements can be added and removed from the stack only at the top. push adds an item to the top of the stack, pop removes
the item from the top. A helpful analogy is to think of a stack of
books; you can remove only the top book, also you can add a new book on
the top.A stack is a recursive data structure. Here is a structural definition of a Stack:
A. Hashing Table :
Hashing table adalah struktur data yang digunakan dalam penyimpanan atau menampung data sementara dan memiliki tujuan untuk mempercepat pencarian kembali dari banyak data yang disimpan.
Distributed Hash Tables are distributed data structures supporting put() and get() primitives on key-value pairs. Most DHT implementations can locate an object in O(logn) network operations, where n is the number of nodes of the DHT, and provide a fault-tolerant way to access large amounts of data. The keyspace is the set of all possible keys. Each node stores a subset of key-value pairs among the keyspace. We say a node N is authority for the key k if it stores its data. Each node also gets assigned an identifier from the keyspace. The DHT defines a distance function between keys. Typically a node N is authority for keys close to its identifier according to that distance. In our study, we do not need the put() operation. The get(k) operation returns the value associated with a key k, performing a lookup in the network, to locate a node that is authority for k. For that purpose a suitable routing algorithm is used, with each node storing a routing table based on the distance among node identifiers.
Hashing table adalah struktur data yang digunakan dalam penyimpanan atau menampung data sementara dan memiliki tujuan untuk mempercepat pencarian kembali dari banyak data yang disimpan.
Operasi-operasi yang ada dalam hashing table :
1. Insert.
2. Search.
3. Delete.
Distributed Hash Tables are distributed data structures supporting put() and get() primitives on key-value pairs. Most DHT implementations can locate an object in O(logn) network operations, where n is the number of nodes of the DHT, and provide a fault-tolerant way to access large amounts of data. The keyspace is the set of all possible keys. Each node stores a subset of key-value pairs among the keyspace. We say a node N is authority for the key k if it stores its data. Each node also gets assigned an identifier from the keyspace. The DHT defines a distance function between keys. Typically a node N is authority for keys close to its identifier according to that distance. In our study, we do not need the put() operation. The get(k) operation returns the value associated with a key k, performing a lookup in the network, to locate a node that is authority for k. For that purpose a suitable routing algorithm is used, with each node storing a routing table based on the distance among node identifiers.
Hash Table and Binary Tree
Hashing
table adalah struktur data yang digunakan dalam penyimpanan atau menampung data
sementara dan memiliki tujuan untuk mempercepat pencarian kembali dari
banyak data yang disimpan.


Operasi-operasi yang ada dalam hashing table :
1. Insert.
2. Search.
3. Delete.
Kelebihan hashing table ialah :
1. Lebih cepat mengakses data dan lebih sedikit menggunakan memory.
2. Kecepatan dalam searchingin, deletions, maupun sertions relatif sama.
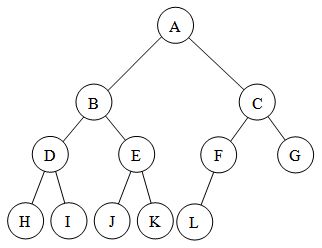
B. Binary Tree
Binary Tree adalah tree yang mempunyai syarat bahwa tiap node atau bagian hanya boleh memiliki maksimal dua (2) subtree atau anak dan kedua subtree atau anak tersebut harus terpisah atau tidak boleh menjadi satu.
Terdapat tipe Binary tree yaitu :
a).Perfect Binary Tree = binary tree yang setiap levelnya memiliki kedalaman yang sama.
a).Perfect Binary Tree = binary tree yang setiap levelnya memiliki kedalaman yang sama.
b).Complete Binary Tree =binary
tree yang setiap levelnya kecuali yang kemungkinan terakhir, terisi dan
setiap nodenya paling panjang ke kiri.Perfect Binary Tree termasuk
dengan Complete Binary Tree.
c).Skewed Binary Tree = binary tree yang memiliki setiap node paling banyak 1 child
d).Balanced Binary Tree = binary tree yang dimana tidak ada leaf yang paling jauh dari root dibanding leaf lainnya.
Operasi-operasi yang ada di dalam Binary Tree :
1. Empty : Memeriksa apakah binary tree masih kosong.
2. Clear : Mengosongkan binary tree yang sudah ada.
3. Create : Membentuk binary tree baru yang masih kosong.
4. Insert : Memasukkan sebuah node ke dalam tree.
5. Find : Mencari root, parent, left subtree, atau right subtree dari suatu node.
6. Update : Mengubah isi dari node yang ditunjuk oleh pointer.
7. DeleteSub : Menghapus sebuah subtree.
8. Retrieve : Mengetahui isi dari node yang ditunjuk pointer.
9. Characteristic : Mengetahui karakteristik dari suatu tree.
10. Traverse : Mengunjungi seluruh node-node pada tree.
Ada tiga cara traverse : Pre Order, In Order, dan Post Order :
#Stack Operation
Push(x) : Menambah data daru yang paling atas.
Pop() : Sama seperti Push tetapi menambah data yang terakhir dimasukan.
Top() : Mengambil data yang paling atas.
#Prefix, Infix, Postfix
Infix : opd opr opd | 4 * 10.
Prefix : opr opd opd | * 4 10.
Postfix : opd opd opr | 4 10 *.
#Circular Queue
Biasanya digunakan atau dipakai dalam OS.
#Deques
Adalah Double Deck Queue dia bisa push sebalah kiri dan kanan, ini biasa dipakai oleh customer service.
Input restricted deque : pushnya dibatasi hanya boleh satu.
Output restricted deque : outputnya dibatasi hanya boleh satu.
#Priority Queue
Biasanya digunakan oleh bank.
#BreadthFirst Search
Bisa digunakan di Multimarketing dan hierarki.
Push(x) : Menambah data daru yang paling atas.
Pop() : Sama seperti Push tetapi menambah data yang terakhir dimasukan.
Top() : Mengambil data yang paling atas.
#Prefix, Infix, Postfix
Infix : opd opr opd | 4 * 10.
Prefix : opr opd opd | * 4 10.
Postfix : opd opd opr | 4 10 *.
#Circular Queue
Biasanya digunakan atau dipakai dalam OS.
#Deques
Adalah Double Deck Queue dia bisa push sebalah kiri dan kanan, ini biasa dipakai oleh customer service.
Input restricted deque : pushnya dibatasi hanya boleh satu.
Output restricted deque : outputnya dibatasi hanya boleh satu.
#Priority Queue
Biasanya digunakan oleh bank.
#BreadthFirst Search
Bisa digunakan di Multimarketing dan hierarki.
Pada pertemuan kedua ini saya mempelajari tentang Linked List, nah linked list ini adalah struktur data yang terdiri dari urutan catatan data sehingga setiap catatan ada bidang yang berisi referensi ke catatan berikutnya dalam urutan. Dan linked terdiri dari dua (2) tipe yaitu :
1. Single Linked List
2. Double Linked List

Contoh daftar yang simpulnya berisi dua bidang:
nilai integer dan tautan ke simpul berikutnya.
Linked list yang simpulnya hanya berisi satu tautan ke simpul lain disebut daftar tertaut tunggal.
Single lingked list: untuk membuat single linked list ini kita harus membuat node struktur terlebih dahulu contoh :
struct
tnode {
int value;
struct tnode *next;
};
struct
tnode *head = 0;
sumber : binusmaya
Langganan:
Komentar (Atom)